 Home-theater-designers
Home-theater-designers
Jako analityk danych często stajesz przed koniecznością łączenia wielu zestawów danych. Musisz to zrobić, aby zakończyć analizę i wyciągnąć wnioski dla swojej firmy/interesariuszy.
Często trudno jest przedstawić dane przechowywane w różnych tabelach. W takich okolicznościach złączenia udowadniają swoją wartość, niezależnie od języka programowania, nad którym pracujesz.
MAKEUSEOF WIDEO DNIA
Sprzężenia Pythona są podobne do złączeń SQL: łączą zestawy danych, dopasowując swoje wiersze do wspólnego indeksu.
Utwórz dwie ramki danych w celach informacyjnych
Aby postępować zgodnie z przykładami w tym przewodniku, możesz utworzyć dwie przykładowe ramki DataFrames. Użyj poniższego kodu, aby utworzyć pierwszą ramkę DataFrame, która zawiera identyfikator, imię i nazwisko.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)W pierwszym kroku zaimportuj pandy biblioteka. Możesz wtedy użyć zmiennej, a , aby przechowywać wynik z konstruktora DataFrame. Przekaż konstruktorowi słownik zawierający wymagane wartości.
Na koniec wyświetl zawartość wartości DataFrame za pomocą funkcji drukowania, aby sprawdzić, czy wszystko wygląda zgodnie z oczekiwaniami.
Podobnie możesz utworzyć kolejną ramkę DataFrame, b , który zawiera identyfikator i wartości wynagrodzenia.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)Możesz sprawdzić dane wyjściowe w konsoli lub IDE. Powinien potwierdzać zawartość Twoich DataFrames:
Czym połączenia różnią się od funkcji scalania w Pythonie?
Biblioteka pandas jest jedną z głównych bibliotek, których można używać do manipulowania DataFrames. Ponieważ ramki DataFrames zawierają wiele zestawów danych, w Pythonie dostępne są różne funkcje umożliwiające ich łączenie.
Python oferuje między innymi funkcje join i merge, których można użyć do łączenia DataFrames. Istnieje wyraźna różnica między tymi dwiema funkcjami, o których należy pamiętać przed użyciem jednej z nich.
Funkcja join łączy dwie ramki DataFrame na podstawie ich wartości indeksu. The funkcja scalania łączy DataFrames na podstawie wartości indeksu i kolumn.
Co musisz wiedzieć o złączeniach w Pythonie?
Zanim omówimy dostępne typy sprzężeń, oto kilka ważnych rzeczy, o których należy pamiętać:
- Sprzężenia SQL to jedna z najbardziej podstawowych funkcji i są dość podobne do złączeń Pythona.
- Aby dołączyć do DataFrames, możesz użyć pandy.DataFrame.join() metoda.
- Domyślne sprzężenie wykonuje sprzężenie lewostronne, podczas gdy funkcja scalania wykonuje sprzężenie wewnętrzne.
Domyślna składnia złączenia Pythona jest następująca:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)Wywołaj metodę join na pierwszej DataFrame i przekaż drugą DataFrame jako jej pierwszy parametr, inny . Pozostałe argumenty to:
- na , który nazywa indeks, do którego ma się przyłączyć, jeśli jest więcej niż jeden.
- Jak , który definiuje typ połączenia, w tym wewnętrzny, zewnętrzny, lewy i prawy.
- lsuffix , który definiuje lewy ciąg sufiksu nazwy kolumny.
- rosuffix , który definiuje prawy ciąg sufiksu nazwy kolumny.
- sortować , który jest wartością logiczną wskazującą, czy posortować wynikową ramkę DataFrame.
Naucz się korzystać z różnych typów złączeń w Pythonie
Python ma kilka opcji złączenia, które możesz ćwiczyć w zależności od potrzeb danej godziny. Oto typy sprzężenia:
1. Lewy dołączyć
Lewe sprzężenie utrzymuje nienaruszone wartości pierwszego elementu DataFrame, jednocześnie wprowadzając pasujące wartości z drugiego. Na przykład, jeśli chcesz wprowadzić pasujące wartości z b , możesz to zdefiniować w następujący sposób:
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)Po wykonaniu zapytania dane wyjściowe zawierają następujące odwołania do kolumn:
- ID_pozostało
- Fname
- Lnazwa
- ID_prawo
- Pensja
To sprzężenie pobiera pierwsze trzy kolumny z pierwszej DataFrame i dwie ostatnie kolumny z drugiej DataFrame. Wykorzystał lsuffix oraz rosuffix wartości, aby zmienić nazwy kolumn identyfikatorów z obu zestawów danych, zapewniając unikatowe nazwy pól wynikowych.
Dane wyjściowe są następujące:

2. Właściwe połączenie
Prawe sprzężenie zachowuje nienaruszone wartości drugiej ramki DataFrame, jednocześnie wprowadzając pasujące wartości z pierwszej tabeli. Na przykład, jeśli chcesz wprowadzić pasujące wartości z a , możesz to zdefiniować w następujący sposób:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)Dane wyjściowe są następujące:
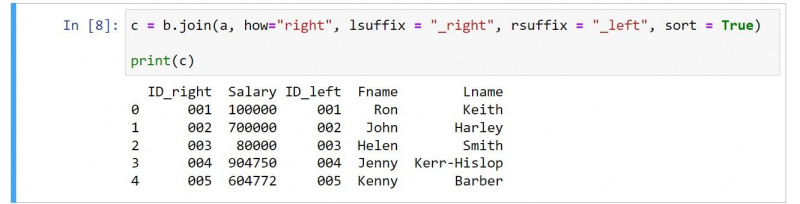
Jeśli przejrzysz kod, jest kilka ewidentnych zmian. Na przykład wynik zawiera kolumny drugiej ramki DataFrame przed kolumnami z pierwszej ramki DataFrame.
Powinieneś użyć wartości prawo dla Jak argument, aby określić prawe sprzężenie. Zwróć też uwagę, jak możesz zmienić lsuffix oraz rosuffix wartości odzwierciedlające charakter prawego sprzężenia.
W przypadku sprzężeń zwykłych możesz częściej używać sprzężeń lewych, wewnętrznych i zewnętrznych w porównaniu ze sprzężeniem prawym. Jednak użycie zależy wyłącznie od wymagań dotyczących danych.
3. Połączenie wewnętrzne
Sprzężenie wewnętrzne dostarcza pasujące wpisy z obu DataFrames. Ponieważ sprzężenia używają numerów indeksu do dopasowywania wierszy, sprzężenie wewnętrzne zwraca tylko te wiersze, które pasują. Na tej ilustracji użyjmy następujących dwóch ramek DataFrame:
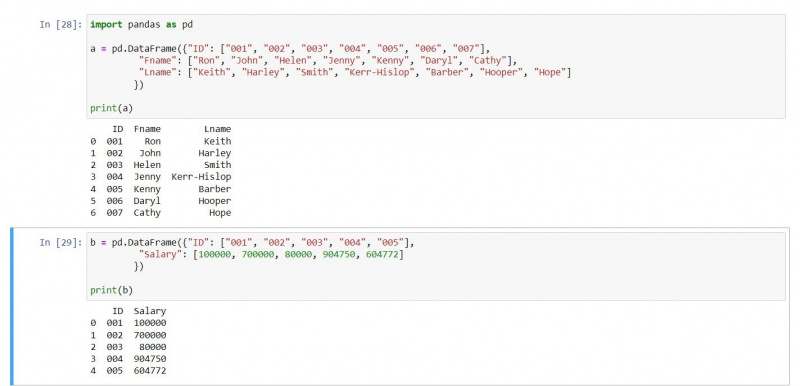
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)Dane wyjściowe są następujące:
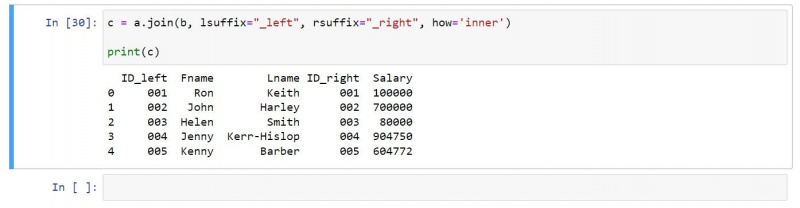
Możesz użyć sprzężenia wewnętrznego w następujący sposób:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)Wynikowe dane wyjściowe zawierają tylko wiersze, które istnieją w obu wejściowych ramkach DataFrames:
4. Połączenie zewnętrzne
Sprzężenie zewnętrzne zwraca wszystkie wartości z obu DataFrames. W przypadku wierszy bez pasujących wartości generuje wartość null w poszczególnych komórkach.
jak wstawić podpis w dokumentach google
Używając tego samego DataFrame co powyżej, oto kod dla zewnętrznego sprzężenia:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)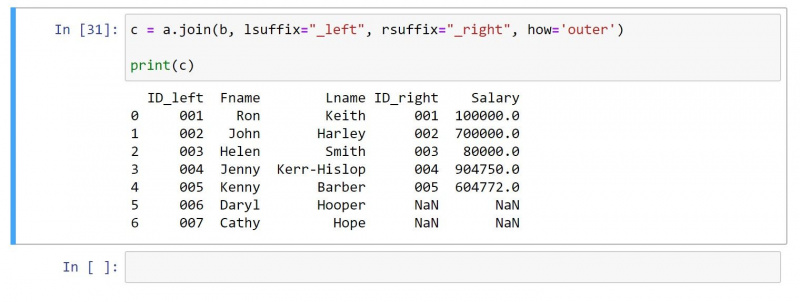
Używanie złączeń w Pythonie
Sprzężenia, podobnie jak ich odpowiedniki, scalanie i łączenie, oferują znacznie więcej niż zwykłą funkcję złączenia. Biorąc pod uwagę szereg opcji i funkcji, możesz wybrać opcje, które spełnią Twoje wymagania.
Otrzymane zbiory danych można sortować stosunkowo łatwo, z funkcją join lub bez niej, dzięki elastycznym opcjom, które oferuje Python.