 Home-theater-designers
Home-theater-designers
Jeśli używasz Pythona, nawet do najprostszych zadań, prawdopodobnie zdajesz sobie sprawę, jak ważne są jego biblioteki innych firm. Biblioteka Pandas, z doskonałym wsparciem dla DataFrames, jest jedną z takich bibliotek.
inny komputer w tej sieci ma taki sam adres IP jak ten komputer
Możesz importować wiele typów plików do Python DataFrames i tworzyć różne wersje do przechowywania różnych zestawów danych. Po zaimportowaniu danych za pomocą DataFrames możesz je scalić w celu przeprowadzenia szczegółowej analizy.
Podstawy
Zanim zaczniesz scalanie, musisz mieć ramki DataFrames do scalenia. Do celów programistycznych możesz utworzyć fałszywe dane, z którymi możesz poeksperymentować.
Utwórz ramki DataFrames w Pythonie
W pierwszym kroku zaimportuj bibliotekę Pandas do pliku Pythona. Pandas to biblioteka innej firmy, która obsługuje DataFrames w Pythonie. Możesz użyć import oświadczenie o korzystaniu z biblioteki w następujący sposób:
import pandas as pdMożesz przypisać alias do nazwy biblioteki, aby skrócić odwołania do kodu.
Musisz stworzyć słowniki, które możesz przekonwertować na DataFrame. Aby uzyskać najlepsze wyniki, utwórz dwie zmienne słownikowe — dyktować1 oraz dykt2 — do przechowywania określonych informacji:
dict1 = {"user_id": ["001", "002", "003", "004", "005"],
"FName": ["John", "Brad", "Ron", "Roald", "Chris"],
"LName": ["Harley", "Cohen", "Dahl", "Harrington", "Kerr-Hislop"]}
dict2 = {"user_id": ["001", "002", "003", "004"], "Age": [15, 28, 34, 24]}Pamiętaj, że musisz mieć wspólny element w obu wartościach słownikowych, aby działał jako klucz podstawowy do późniejszego łączenia ramek DataFrames.
Konwertuj swoje słowniki na ramki danych
Aby przekonwertować wartości słownikowe na DataFrames, możesz użyć następującej metody:
df1 = pd.DataFrame(dict1)
df2 = pd.DataFrame(dict2)Niektóre IDE pozwalają sprawdzić wartości w DataFrame, odwołując się do funkcji DataFrame i naciskając Uruchom/Wykonaj . Jest wiele IDE kompatybilne z Pythonem , dzięki czemu możesz wybrać ten, który jest dla Ciebie najłatwiejszy do nauczenia.

Gdy będziesz zadowolony z zawartości swoich ramek DataFrames, możesz przejść do kroku scalania.
Łączenie ramek z funkcją scalania
Funkcja scalania jest pierwszą funkcją Pythona, której możesz użyć do połączenia dwóch ramek DataFrame. Ta funkcja przyjmuje następujące argumenty domyślne:
pd.merge(DataFrame1, DataFrame2, how= type of merge)Gdzie:
- pd to alias biblioteki Pandas.
- łączyć to funkcja, która łączy DataFrames.
- Ramka danych1 oraz Ramka danych2 to dwie ramki DataFrame do połączenia.
- Jak definiuje typ scalania.
Dostępne są dodatkowe argumenty opcjonalne, których można użyć, gdy masz złożoną strukturę danych.
Możesz użyć różnych wartości parametru how, aby zdefiniować typ scalania do przeprowadzenia. Te rodzaje scalania będą znajome, jeśli: używał SQL do łączenia tabel bazy danych .
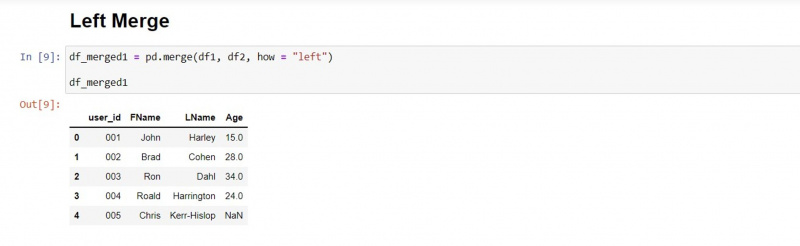
Scal z lewej
Lewy typ scalania zachowuje nienaruszone wartości pierwszego DataFrame i pobiera pasujące wartości z drugiego DataFrame.
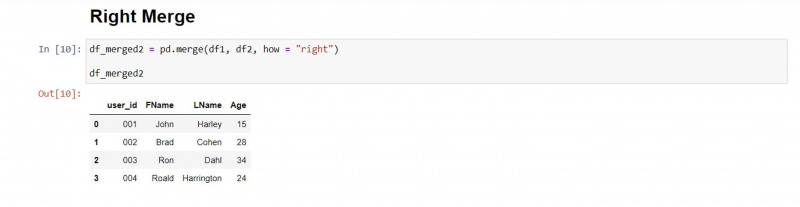
Prawe scalanie
Prawy typ scalania zachowuje nienaruszone wartości drugiej ramki DataFrame i pobiera pasujące wartości z pierwszej ramki DataFrame.
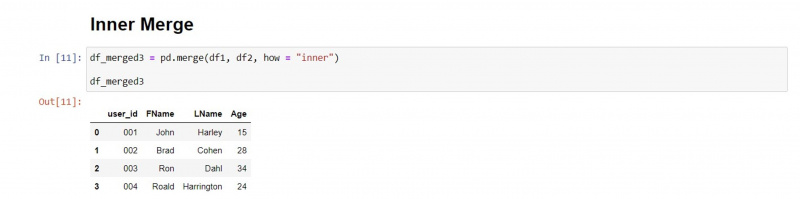
Scalanie wewnętrzne
Wewnętrzny typ scalania zachowuje pasujące wartości z obu DataFrames i usuwa wartości niezgodne.
Scalanie zewnętrzne
Zewnętrzny typ scalania zachowuje wszystkie pasujące i niepasujące wartości oraz konsoliduje DataFrames razem.

Jak korzystać z funkcji Concat
The concat function to elastyczna opcja w porównaniu do niektórych innych funkcji scalających Pythona. Dzięki funkcji concat możesz łączyć DataFrames w pionie i poziomie.
Jednak wadą korzystania z tej funkcji jest to, że domyślnie odrzuca wszystkie niepasujące wartości. Podobnie jak niektóre inne pokrewne funkcje, ta funkcja ma kilka argumentów, z których tylko kilka jest niezbędnych do udanej konkatenacji.
concat(dataframes, axis=0, join='outer'/’inner’)Gdzie:
- concat to funkcja, która łączy DataFrames.
- ramki danych to sekwencja ramek DataFrames do połączenia.
- oś reprezentuje kierunek konkatenacji, 0 oznacza poziom, 1 pion.
- Przystąp określa sprzężenie zewnętrzne lub wewnętrzne.
Korzystając z powyższych dwóch ramek DataFrames, możesz wypróbować funkcję concat w następujący sposób:
# define the dataframes in a list format
df_merged_concat = pd.concat([df1, df2])
# print the results of the Concat function
print(df_merged_concat)Brak osi i argumentów złączenia w powyższym kodzie łączy dwa zestawy danych. Wynikowe dane wyjściowe zawierają wszystkie wpisy, niezależnie od statusu dopasowania.
Podobnie możesz użyć dodatkowych argumentów, aby kontrolować kierunek i dane wyjściowe funkcji concat.
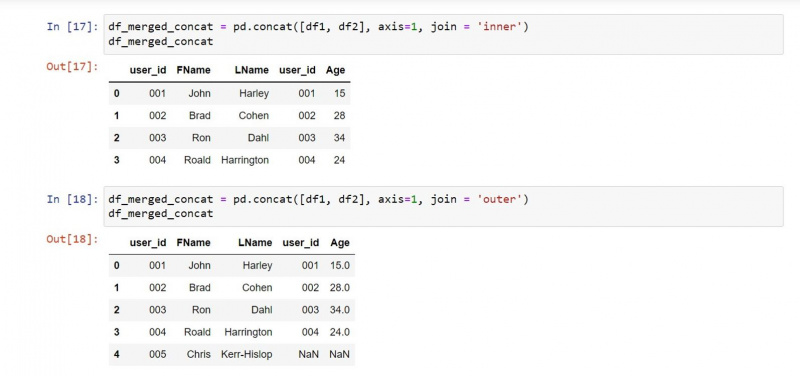
Aby sterować wyjściem za pomocą wszystkich pasujących wpisów:
# Concatenating all matching values between the two dataframes based on their columns
df_merged_concat = pd.concat([df1, df2], axis=1, join = 'inner')
print(df_merged_concat)Wynik zawiera wszystkie pasujące wartości tylko między dwiema ramkami DataFrames.
jak wykryć złośliwe oprogramowanie na iPhonie
Scalanie ramek danych z Pythonem
Ramki DataFrame są integralną częścią Pythona, biorąc pod uwagę ich elastyczność i funkcjonalność. Biorąc pod uwagę ich wieloaspektowe zastosowania, możesz z nich korzystać w szerokim zakresie do wykonywania różnych zadań z największą łatwością.
Jeśli nadal uczysz się o Python DataFrames, spróbuj zaimportować niektóre pliki Excela, a następnie połącz je z różnymi podejściami.